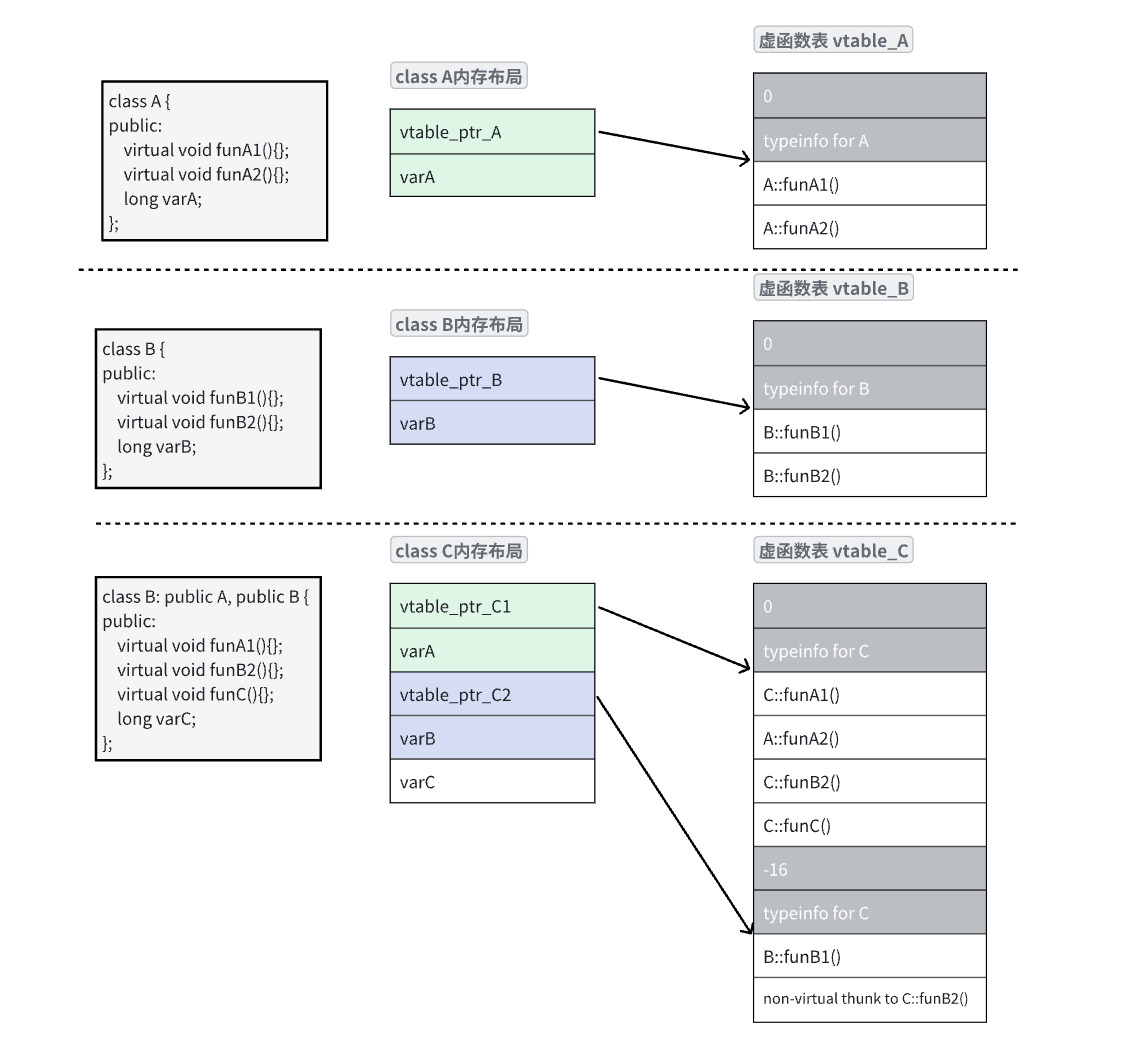
C++ 包管理方案
为什么 C++ 没有一个统一的包管理器
很多主流语言都有自己的包管理方案,比如 Python 的 pip, JavaScript 的 npm, Java中的 Maven 等,但是 C++ 并没有一个统一的包管理方案,归根到底有一定的历史原因。C++ 标准在不断地演进,C++98,C++03,到现代的C++11/14/17/20等,每个版本都引入一些新特性,在这些标准当中引入一个官方的包管理器要考虑到前后兼容性和现有系统的影响。另外 C++ 的生态系统非常庞大和多样化,涵盖了不同的编译器,操作系统,硬件平台等,一个官方的 C++ 管理器平台如何实现需要各个社区达成一致,制定一个统一的标准,这是一个复杂且需要时间的过程。
没有包管理器的开发环境是怎样的
首先,项目规模不大的话,有没有包管理器是影响不大的,选定好平台,安装或者自己编译需要的库一直用发下去就可以了。
但如果项目规模变大可能就会出现问题,依赖项管理困难,团队成员可能需要手动,安装和管理各种依赖和第三方库。进而会导致另外一个问题,版本控制和一致性,每个团队成员手动管理依赖项的时候,可能会使用不同版本的库或者工具,增加代码的不稳定性,出现一些潜在的BUG。
同时手动维护依赖会导致很多流程无法自动化,CI/CD等无法实施 随着团队规模变大,需要投入更大的时间和精力去管理这些流程,慢慢就会变得不可持续。
包管理的各个阶段
- 原生拷贝。各个团队成员直接拷贝代码或者库文件给他人使用,且没有版本管理。
- 加入版本管理。每个团队维护好自己的代码库,通过CI自动构建,供别人下载使用。
- 加入依赖管理。提供一定的策略,获取递归的获取代码库所有依赖。
- 解决依赖冲突。当设计到依赖冲突的时候,提供策略解决冲突问题。
- 多平台支持。支持不同的架构,操作系统。
一种包管理平台的设计思路
Conan, 一个开源的C++包管理器工具,虽然没有被大规模普及,但是它的一些策略和方案,可以用来学习。
首先一个 C++ 包需要有哪些属性,一个软件包最终都是编译成二进制,所以就要考虑二进制库文件有哪些属性,首先是二进制包是怎么来的
- 构建包的体系架构(x86/arm/???),操作系统(Linux/Windows/MacOS/???), 编译器(gcc/clang/msvc/???), 编译器版本,等平台的属性。
- 编译选项,比如静态库还是动态库,某些编译选项等包自定义的一些属性。
- 依赖项。依赖哪些项目,对项目的依赖粒度,比如是否限制大版本或者小版本。
如果只管理二进制包,即编译之后的库文件,只需要上面这些属性就可以了。同一个版本比如 OpenCV/3.4.2 在不同架构,操作系统,编译器,编译选项下可能会产生数十个版本。其他用户下载固定包的时候也会带上自己的平台属性,然后找到对应的包传递给客户即可。有上面的匹配机制,就保证下载下来的一定是兼容的。
如果不想直接管理二进制库,想要通过管理源代码的方式管理各个平台的二进制库还需要更复杂的策略,比如获取源代码的方式,构建方式,打包方式等。